
| Prev page | Next page |
| FAR 117 versus FAR 121 subpart Q | FAR 117 versus FAR 121 subpart Q |
By Garret Healy, Software Engineer, Jeppesen Inc.
Joshua Foltz, First Officer, Allegiant Air
Abstract:
The author’s developed the following tables as a crew planning tool. These tables demonstrate how strict FAR Part 117 work rules are in relation to allowed duty time when compared to FAR part 121 subpart R and S.
Airlines must schedule efficient Flight Duty Periods and carefully plan when Flight Duty Periods begin as well as how many segments are involved.
In order to schedule efficient pairings the Airlines should consider looking at productive hours (block time) versus non-productive hours (FDP time).
Since not all augmented operations involve acclimatization issues, we have also allowed for the ability to examine operations when the penalty for un-acclimated FDP may be applied.
Definitions:
Acclimated
means a condition in which a flightcrew member has been in a theater for 72 hours or has been given at least 36 consecutive hours free from duty.
Augmented flightcrew
means a flightcrew that has more than the minimum number of flightcrew members required by the airplane type certificate to operate the aircraft to allow a flightcrew member to be replaced by another qualified flightcrew member for in-flight rest.
Duty:
Is defined in FAR part 117.
Means any task that a flightcrew member performs as required by the certificate holder, including but not limited to flight duty period, flight duty, pre- and post-flight duties, administrative work, training, deadhead transportation, aircraft positioning on the ground, aircraft loading, and aircraft servicing.
Pre-Flight Duties:
Includes reporting for an assignment, acknowledging flights to be performed while on duty, will be operated in accordance to FAA regulations, including understanding of the expected conditions that will affect the flight(s) to be performed. Inspections of the aircraft for flight readiness, etc.
Flight Duty Period (FDP):
Is defined in FAR part 117.
Means a period that begins when a flightcrew member is required to report for duty with the intention of conducting a flight, a series of flights, or positioning or ferrying flights, and ends when the aircraft is parked after the last flight and there is no intention for further aircraft movement by the same flightcrew member. A flight duty period includes the duties performed by the flightcrew member on behalf of the certificate holder that occur before a flight segment or between flight segments without a required intervening rest period. Examples of tasks that are part of the flight duty period include deadhead transportation, training conducted in an aircraft or flight simulator, and airport/standby reserve, if the above tasks occur before a flight segment or between flight segments without an intervening required rest period.
Flight Time:
Is defined in FAR part 1.
Commences when an aircraft moves under its own power for the purpose of flight and ends when the aircraft comes to rest after landing.
Flightcrew Member (FCM):
Is defined in FAR part 1.
Is a pilot, flight engineer, or flight navigator assigned to duty in an aircraft during flight time.
Assumptions:
Brief time:
The amount of pre-flight duty before the flight departs the gate. Typically ranges between 0:45 to 1:00; generally contained within a CBA; for the purposes of this paper we will use 1:00.
Debrief time:
The amount of post-flight duty after the flight arrives at the gate. Typically ranges between 0:15 to 0:30; generally contained within a CBA; for the purposes of this paper we will use 0:15.
Flight Time Buffer:
The amount of time used to schedule a FCM within the permissible limitations of FAR part 117.11, for the purposes of this paper we will use 0:30.
Minimum Connect Time:
The minimum time from when an aircraft arrives at the gate, to the time when the aircraft moves away from the gate to allow for sufficient to unload/load passengers and baggage, and make any required service needs for the aircraft before departure as well as performance of pre-flight checklists, for the purposes of this paper we will use 0:45.
Permissible Extensions to FDP:
Under FAR 117.19, it is permissible to operate beyond the scheduled limitations in FAR 117.13 by 0:30, extensions up 2:00 may be conducted before departure under certain conditions, for the purposes of this paper we will use 0:30.
Cumulative Flight Time Limitations:
For the purposes of this paper, a FCM will not be exceeding any of the following limitations:
- Under 117.23, FCM’s are limited to 100 hours in 672 consecutive hours and 1000 hours in 365 calendar days.
- Under 121 subpart R and S, FCM’s are limited to 30 or 32 hours in 7 calendar days depending upon the type of operation, 100 / 120 hours in a calendar month / 30 calendar days and 1000 hours in a calendar year / 12 Calendar Months.
Cumulative Flight Duty Time Limitations:
For the purposes of this paper, a FCM will not be exceeding any of the following limitations:
- Under 117.23, FCM’s are limited to 60 hours in 168 consecutive hours and 190 hours in 672 consecutive hours.
- Under 121 subpart R and S, FCM’s are presently not limited by FDP time.
Rest Requirements:
For the purposes of this paper, a FCM will always be in compliance with the following requirements:
- Under 117.25, FCM’s are required to have been scheduled for and have been given a rest period of no less than 30 hours in the 168 consecutive hours preceding the start of a FDP.
- Under 121 subpart R and S, FCM’s are required to have been scheduled for and have been given a rest period of no less than 24 hours in the 7 calendar days preceding the scheduled completion of any flight subject to this subpart.
Flight segment count:
Under FAR 117, the maximum number of Flight segments that may be scheduled is 3 for Augmented operations.
FAA’s rational for the determination of FTL and FDP limits for Augmented Flightcrew:
With regards to FTL:
The FAA stated in the FNPRM that 13 hours for 3 pilot crews and 17 hours for 4 pilot crews would not impact safety.
With a 3 pilot crew the maximum flight deck duty time is 8:40 = (2/3)*13:00.
With a 4 pilot crew the maximum flight deck duty time is 8:30 = (2/4)*17:00.
Both of these values fall into the range for un-augmented operations of 8 to 9 hours.
With regards to FDP:
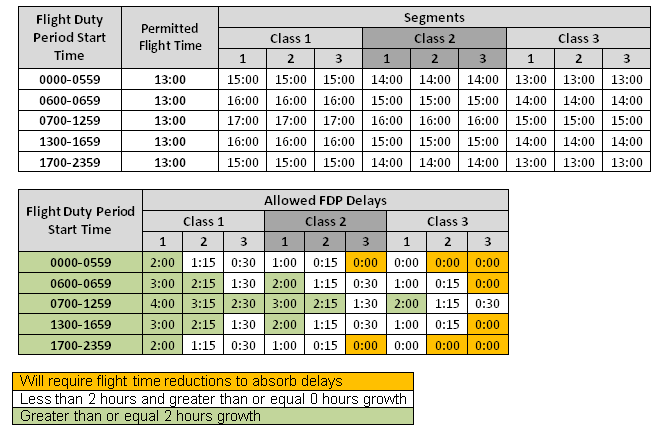
The FAA used the same diurnal concept used in un-augmented operations, basing the limitations on FDP start time. The FAA further refined the limitations on the number of pilots assigned to the FDP as well as the type of onboard rest facility. The limitations are presented in Table C.
Conceptual differences under FAR 117:
Under FAR 121 subpart Q, no credit is given to a FCM who is assigned to an augmented crew.
The only credit given to augmented operations for domestic operations is under FAR 121 subpart S, “Mainland Rules”.
Under FAR 121 subparts R and S, augmented operations had little details concerning onboard rest facilities, no limitations concerning the number of flight segments, and no specific onboard rest requirements for FCM apart from a differentiation of flight deck duty and time aloft as a FCM.
Under FAR 117, augmentation may take place under domestic or international operations; thus allow carriers additional flexibility.
Objective comparisons of specific regulatory provisions:
Daily Flight Time Limitations (FTL):
Part 117 has Daily FTL’s governed under 117.11.
- Based upon the number of FCM’s assigned to a FDP, the limitation is either
- 13:00 for 3 Pilots
- 17:00 for 4 Pilots.
- Evaluated on a leg by leg basis, FCM may not continue a flight if before takeoff it is known that the FTL will be violated.
Part 121 has Daily FTL’s governed under FAR 121 subpart S
- Subpart S is broken up into two distinct sections
- “Main Land” operations solely within the 48 States
- “International” operations that include stations outside the 48 states.
- Mainland Rules:
- Under 121.505(a), a 2 pilot crew may not be scheduled for more than 8:00, this limitation sets a base line used in the establishment further limitations under this subpart.
- Under 121.507(a)(2), a 3 pilot crew may not be scheduled for more than 12:00.
- Under 121.509(a)(2), a 4 pilot crew may not be scheduled for more than 16:00.
- International Rules:
- Under 121.521(a), a 3 pilot crew may not be scheduled for more than 12:00.
- Under 121.523(b), a 4 pilot crew is required to have adequate rest periods on the ground while away from base, although no specific FTL is specified, it has regularly been interpreted as 16:00.
- Part 121 has Daily FTL’s governed under FAR 121 subpart R.
- Under 121.481(a) and (b), a 2 pilot crew may not be scheduled for more than 8:00, this limitations sets a base line used in the establishment further limitations under this subpart.
- Under 121.483(a), a 3 pilot crew may not be scheduled for more than 12:00.
- Under 121.485(a), a 4 pilot crew is required to have adequate rest periods on the ground while away from base, although no specific FTL is specified, it has regularly been interpreted as 16:00.
Daily FDP Limitations:
Part 117 has Daily FTL’s governed under 117.17.
- Based upon FDP start time, The number of FCM assigned and the class of the onboard rest facility; the scheduled limitation is defined in Table C.
- Extensions to the assigned FDP are permitted in accordance with 117.19.

Table C
Part 121 does not actually have FDP limitations, instead duty time limitations will be used:
- FAR 121 subpart S “Mainland Rules”:
- 2 Pilots – 16:00 Duty Limit
- 3 Pilots – 18:00 Duty Limit
- 4 Pilots – 20:00 Duty Limit
- FAR 121 subpart S “International Rules” and FAR 121 subpart R:
- These sections do not actually establish duty limits, but best practices and many contractual limitations will establish duty limits like those for the “Mainland Rules”.
- For the purposes of our research, we will apply these methods as well.
Objective comparisons of specific regulatory provisions:

Some operations will be performed while a FCM is in an unacclimated state, in those cases a 0:30 penalty to the FDP must be assessed under FAR part 117.
FAR 121 Subpart S “Mainland Rules”
(Max Duty Time – Max Extension) – ((Max Flight Time – Flt buffer) + Brief + Debrief + (Segments – 1) * Turn) = Allowed Flight Duty Period delay

Relative Efficiency of the FDP
100 * (Max Flight Time)/((max duty time – debrief) + Permitted Pairing Growth) * (2/Flightcrew size)

FAR 117 – 3 Pilots
((Max Skd FDP – Unacclimated Penalty)+ Max Extension) – ((Max Flight Time – FT Buffer) + Brief + (Segments – 1) * Turn) = Allowed Flight Duty Period delay
((Max Skd FDP- Unacclimated Penalty) + Max Extension) – ((Max Flight Time) + Brief + (Segments – 1) * Turn) = Required Reduction of Flight Time

Relative FDP Efficiency
100 * (Max Flight Time- Required reduction of Flight Time)/((max skd FDP – unacclimated penalty) + Permitted Pairing Growth) * (2/3)

FAR 117 – 4 Pilots
((Max Skd FDP – Unacclimated Penalty)+ Max Extension) – ((Max Flight Time – FT Buffer) + Brief + (Segments – 1) * Turn) = Allowed Flight Duty Period delay

((Max Skd FDP- Unacclimated Penalty) + Max Extension) – ((Max Flight Time) + Brief + (Segments – 1) * Turn) = Required Reduction of Flight Time

Relative FDP Efficiency
100 * (Max Flight Time- Required reduction of Flight Time)/((max skd FDP – unacclimated penalty) + Permitted Pairing Growth) * (2/4)

Conclusions:
FAR 117 when compared to FAR part 121 subparts R and S augmented operations, overall the pairings will be more efficient; this is primarily due to the fact that flight deck time has increased by 30 to 40 minutes.
Like part 121 operations, 3 pilot operations under part 117 will be more efficient compared to 4 pilot operations. We also see that the ability to accept delays with an increase in the number of segments decreases under both part 121 and part 117.
While part 117 has different limitations based upon the class of the onboard rest facility that will reduce the permissible FDP limitations, this seems to increase the efficiency across both 3 and 4 pilot.
FDP’s that start between 0700 and 1259 have the best ability to accept delays “the sweet spot”, while those between 1700 and 0559 are more prone to the negative effects associated with delays.
FDP’s that use a class 1 rest facility have the best ability to accept delays, while class 3 have the worst ability, due to the diminished FDP limitations.
We also examined longer brief/debrief/turn times, to emulate different contractual requirements to account for the clearing of customs and immigration, which equally diminished FAR 117 and FAR 121 operations.
Increased turn times are also to be expected with larger aircraft and higher passenger capacities, but it is still felt that the formulas used are valid and properly present the concepts.
Lastly we looked at the application of the unacclimated penalty, as this factor will only apply to part 117, it should diminish efficiency by approx. 1.08 percent, and reduce the ability to accept delays by 0:30.
Recommendations:
The authors’ recommend that augmented FDP’s be scheduled for 1 or 2 segments especially when using a class 3 rest facility to prevent disruptions due to delays, apply realistic buffers for connections times to help mitigate delays.


